[프로그래머스 / python / Level 3] 표 병합
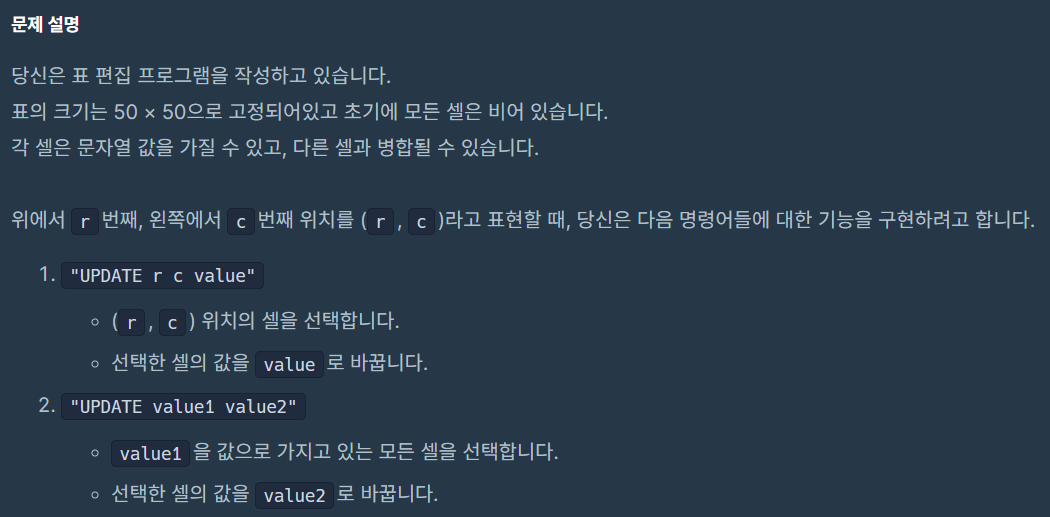

2023 KAKAO BLIND RECRUITMENT에 출제된 문제로써, Union-Find가 사용되는 문제이다.
Union-Find는 특정 그룹으로 묶고, 나누고, 그룹을 찾고 하는 것에 특화된 알고리즘이며, 표 병합같은 문제에 딱 맞는 알고리즘이다.
def solution(commands):
"""
find: 대표를 찾는 함수, 재귀 구현
union: 병합 함수, merge 구현
"""
"""1차원 리스트 사용, 처음엔 자기 자신이 대표"""
parent = [i for i in range(2601)]
values = ["" for _ in range(2601)] # 처음엔 전부 빈 값
"""좌표를 1차원 인덱스로 변환하는 함수"""
def get_idx(r, c):
return r * 51 + c
"""1차원 인덱스를 좌표로 변환하는 함수"""
def get_coordinate(idx):
return (idx // 51, idx % 51)
"""
해당 좌표의 대표를 리턴하는 함수
대표를 찾는 재귀호출 과정에서 거치는, 모든 좌표의 부모를 대표로 바꾼다
"""
def find(idx):
if idx != parent[idx]: # 자기 자신이 대표가 아닐 경우
parent[idx] = find(parent[idx])
return parent[idx]
"""병합 함수"""
def union(x, y):
x_root = find(x)
y_root = find(y)
# 이미 같은 그룹이면 병합하지 않는다
if x_root == y_root:
return
if values[y_root] == "":
parent[y_root] = x_root
elif values[x_root] == "":
parent[x_root] = y_root
else:
parent[y_root] = x_root
"""메인 로직"""
result = []
for command in commands:
cmd = command.split()
if len(cmd) == 4:
"""UPDATE r c value"""
r, c = map(int, cmd[1:3])
value = cmd[-1]
# 대표의 값을 변경
root = find(get_idx(r, c))
values[root] = value
elif len(cmd) == 5:
"""MERGE r1 c1 r2 c2"""
r1, c1, r2, c2 = map(int, cmd[1:])
idx1 = get_idx(r1, c1)
idx2 = get_idx(r2, c2)
# 병합
union(idx1, idx2)
elif cmd[0] == 'UPDATE':
"""UPDATE value1 value2"""
value1, value2 = cmd[1], cmd[2]
# 대표의 값만 바꾼다
for i in range(2601):
if parent[i] == i and values[i] == value1:
values[i] = value2
elif cmd[0] == 'UNMERGE':
"""UNMERGE r c"""
r, c = map(int, cmd[1:])
origin_idx = get_idx(r, c)
root_idx = find(origin_idx)
saved_value = values[root_idx]
# r,c와 같은 그룹의 모든 셀을 독립적으로 바꾸고 값을 지운다
unmerge_list = []
for idx in range(2601):
if root_idx == find(idx):
unmerge_list.append(idx)
for idx in unmerge_list:
parent[idx] = idx
values[idx] = ""
# 지정 셀만 기존 값 복원
values[origin_idx] = saved_value
elif cmd[0] == 'PRINT':
"""PRINT r c"""
r, c = map(int, cmd[1:])
root_idx = find(get_idx(r, c))
value = values[root_idx]
if value == '': value = 'EMPTY'
result.append(value)
return result
문제에서 주어진 표의 크기는 50 * 50으로 고정되어 있다. 즉 2차원 배열인데, 편리하게 다루기 위해 1차원 배열로 변경한다.
2차원 -> 1차원 변환 공식은 다음과 같다.
2차원 -> 1차원 변환
크기: 50 * 50
좌표: (3,4)
0 based
배열 크기: rows * cols
1차원 인덱스 변환: r * cols + c
2차원 인덱스 추적: idx // cols, idx % cols
-> 2500, 154, (3, 4)
1 based
배열 크기: (rows + 1) * (cols + 1)
1차원 인덱스 변환: r * (cols+1) + c
2차원 인덱스 추적: idx // (cols+1), idx % (cols+1)
-> 2601, 157, (3, 4)
이 문제는 1 based가 기준인 문제이다. 따라서 배열 크기는 51 * 51 = 2601 로 설정한다.
parent[i]는 i의 부모 인덱스를 의미한다. 만약 parent[i] == i 일 경우, 자기 자신이 대표라는 뜻이다.
values[i]는 i 위치에 있는 값을 의미한다. 우리는 이 문제에서, 대표 위치에만 값을 저장하고 갱신할 것이다.
find 함수가 핵심인데, 자기 자신이 대표가 아닐 경우 재귀적으로 parent 를 따라가며 최종 대표를 찾는다. 또한 재귀호출 과정에서 거치는 모든 그룹원들의 parent 값을 대표의 값으로 바꾼다. 즉, 5번 재귀를 거쳐 대표를 한번 찾았다면 그 다음 대표 탐색 과정에서는 5번이 아니라 단 한번 O(1)에 대표를 찾을 수 있다는 뜻이다. 이것을 경로 압축이라고 하며, Union-Find 알고리즘의 핵심이다.
union 함수는 병합 함수이다. x, y 두 좌표를 받아서 특정 한 그룹에게 병합한다. 병합은 한 그룹의 대표가 나머지 한 그룹의 대표를 부모로 가짐으로써 이루어진다.
나머지 명령어 파싱 및 분기처리는 많이 어렵진 않았다. 조건이 많고 복잡해서 구현할 때 실수가 잦을 수 있다는 것 뿐이지, 요구사항 자체가 이해하기 어려운 정도는 아니었다. 문제 요구사항을 잘 읽고 집중해서 구현하면 된다.
그런데 한 가지 신경써야 할 부분이 있다.
# UNMERGE 로직 일부
# 문제 코드
for idx in range(2601):
if root_idx == find(idx):
parent[idx] = idx
values[idx] = ""
# 통과 코드
unmerge_list = []
for idx in range(2601):
if root_idx == find(idx):
unmerge_list.append(idx)
for idx in unmerge_list:
parent[idx] = idx
values[idx] = ""
여긴 UNMERGE 코드의 일부인데, 한 그룹을 분쇄시키는 로직이다. 같은 대표를 가진, 즉 같은 그룹의 모든 그룹원들을 독립적으로 만들고 그룹을 해체하는 것이다.
코드를 보면 문제 코드는 그룹원을 찾자마자 독립시키고, 통과 코드는 그룹원을 미리 전부 찾은 후 독립시킨다. 즉 탐색과 독립이 따로다.
그냥 보면 별 차이 없어 보이지만, 첫 번째 코드에서 find() 가 문제가 될 수 있다. find()는 대표를 찾는 역할도 하지만, 대표를 찾으면서 거쳐간 그룹원들의 parent를 전부 대표로 수정한다. 얼핏 보면 아무 문제 없어 보일 수 있지만, 탐색 -> 바꾸기 -> 탐색 -> 바꾸기 하는 과정에서 그룹원들의 연관관계가 꼬여 문제가 일어난다.
3 -> 1 -> 5 -> 7(대표) 관계가 있다고 했을 때,
parent[1]을 1로 바꿨을 경우, (독립)
find(3)을 하면 7까지 이어져야 했지만 1은 자기 자신을 가리키므로 7까지 이어지지 못하고 끊어져 버린다.
따라서 통과 코드처럼, 독립시킬 그룹원을 미리 전부 찾은 후 parent를 바꿔 줘야 예기치 못한 문제가 발생하지 않는다. 이런 점들은 이 문제에서뿐만 아니라, 실무 비즈니스 로직을 작성할 때도 신경써줘야 한다고 생각한다.