동적 메모리 할당
- heap 영역에서 이루어진다.
- heap은 위쪽으로(높은 주소 방향으로) 성장한다.
- heap의 top(높은 주소 쪽)을 가리키는 변수는 “brk”이며 break로 발음한다.
- 할당기는 힙을 다양한 크기의 블록들의 집합으로 관리한다.
- 각 블록은 할당된 블록과, 가용된 가상메모리의 연속적인 묶음이다.
명시적 할당기 - malloc
- malloc을 호출해서 메모리 블록을 할당한다.
- free를 호출해서 메모리 블록을 반환한다.
묵시적 할당기 - garbage collector
- 할당된 블록이 언제 반환되어야 하는지 할당기가 알고 있다
- 사용되지 않는 블록을 자동으로 반환하는 작업을 “garbage collection" 이라고 부른다.
- List, ML, Java 같은 언어들은 garbage collection을 사용한다.
## malloc이 명시적 할당기 인 것과, malloc 내부에서 묵시적/명시적 가용 리스트를 사용하는 것은 별개이다.
## 즉 malloc은 명시적 할당기이지만 내부에서 묵시적 가용 리스트를 사용할 수 있다.
malloc 함수
- void *malloc(size_t size);
- C표준 라이브러리는 malloc 함수를 호출하여 힙 영역의 메모리 블록을 할당받는다.
- malloc은 입력받은 byte 크기를 갖는 메모리 블록의 포인터(메모리 주소)를 리턴한다. (정확히는 payload 블록이 입력받은 byte와 일치한다)
- 32비트에서는 8의 배수, 64비트에서는 16의 배수 주소를 리턴한다.
- 가용할 수 없을 만큼 큰 메모리 블록을 요청받을 경우, malloc은 NULL을 return하고 errno를 설정한다. ( ENOMEM 으로 설정 )
- malloc은 리턴하는 메모리를 초기화하지 않는다.(가비지 값이 있는 채로 준다)
- calloc 함수는 리턴하는 메모리를 각각 0으로 초기화하며, realloc 함수는 이미 할당된 블록의 크기를 변경할 수 있다.
- malloc은 mmap, munmap 함수를 이용해 명시적으로 힙을 할당/반환하고 sbrk 함수도 사용할 수 있다.
sbrk 함수
- void *sbrk(intptr_t incr);
- sbrk는 brk 포인터에 incr을 더하여 힙을 늘리거나 줄인다.
- 성공하면 ”이전의 brk값“ return, 실패하면 -1 return 후 errno를 ENOMEM으로 설정한다.
- incr이 0 이었다면 현재 brk 값을 반환한다.
- 첫 번째 가용이 아니었을 때, brk는 기존 epBlock의 바로 뒤 블록을 가리킨다.
free 함수
- void *free(void *ptr);
- 할당된 힙 블록을 free함수를 호출하여 반환한다.
- ptr 인자는 malloc, calloc, realloc 등에서 할당받은 메모리 블록의 시작 주소를 가리켜야 한다. ( 헤더 1워드 뒤, 페이로드 블록의 포인터 )
- 그렇지 않으면 free는 동작하지 않으며, free는 아무것도 return하지 않기 때문에 잘못된 것을 알 수도 없다. 여기서 런타임 에러를 유발할 수 있으므로 free의 인자를 잘 확인해야 한다.
아래는 malloc과 free의 사용에 의한 메모리의 변화와 포인터를 표현한 것이다.
한 칸은 워드(4바이트)이며, 더블워드(8바이트) 단위로 할당하거나 해제할 수 있다.
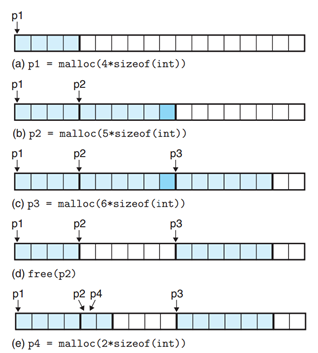
a : 16바이트를 할당했다.
b : 20바이트를 할당 요청했지만 더블 워드 단위로 할당되기 때문에 24바이트가 할당되었다. 단위 때문에 추가된 1바이트는 패딩되었다고 표현한다. ( 패딩 블록 )
c : 24바이트를 할당했다.
d : p2를 할당 해제했다. 하지만 p2의 포인터는 계속해서 해당 주소를 가리키고 있다. dangling pointer가 된 것이다. 이 때는 p2의 값을 NULL로 바꿔 주거나 이 주소에 접근하지 말아야 한다.
e : 8바이트를 할당했다. 현재 예시는 first-fit 기준(힙의 앞쪽 블록부터 탐색)이므로 가장 먼저 나오는 p2 위치에 그대로 p4가 할당되었다.
동적 메모리 할당을 하는 이유
- 프로그램을 실행시키기 전에는 자료구조의 크기를 알 수 없는 경우들 때문
- ex) 사용자에게 입력받은 만큼 배열이 필요할 경우
할당기의 요구사항
1. 요청에 즉시 응답하기
할당기는 즉시 응답해야 한다. 성능 향상을 위해 요청을 재정렬하거나 버퍼링하면 안 되며, 요청을 받고 그 요청에 즉시 응답한다.
2. 힙만 사용하기
힙은 확장성을 가지기 때문에 동적 할당을 위해서는 힙 영역만 사용하여 메모리를 할당해야 한다.
3. 블록 정렬하기
할당기는 블록에 어떤 종류의 데이터 객체라도 저장할 수 있는 방식으로 정렬되어야 한다.
4. 할당된 블록을 수정하지 않기
할당기는 가용 블록을 할당/해제만 할 수 있다. 즉 일단 블록이 할당되면 수정/이동이 불가하다.
(realloc은 해제한 후 다시 할당하는 형태이다)
할당기의 목표
1. 처리량 극대화하기
- 단위 시간당 처리하는 요청의 수를 최대화 해야 한다. ex) 1분에 100개 연산보단 200개 연산이 더 좋다
2. 메모리 이용도를 최대화하기
- 메모리가 낭비되는 부분이 없게 최대한 많은 부분을 이용해야 한다.
- 할당된 가상메모리의 양은 디스크 내의 스왑 공간의 양으로 제한된다. 가상메모리는 무한 자원이 아니며, 따라서 최대한 효율적으로 사용해야 한다. 이를 유용하게 표현할 수 있는 단위를 ”최고 이용도(peak utilization)" 라고 한다.
- 단, 처리량과 이용도는 반비례하는 경향이 있기 때문에, 두 목표 사이에서 균형을 찾는 것이 중요하다.
ex) 이용도를 올리기 위해 많은 조건을 달면 처리속도가 떨어지는 경우
단편화
- 메모리 이용도가 낮은 경우, 주요 이유는 “단편화” 현상 때문이다.
- 단편화는 내부/외부 단편화로 나뉜다.
내부 단편화
- 할당된 “블록이 데이터보다 더 클 경우” 일어난다.
- ex) 요청 데이터보다 블록 최소 할당 크기가 더 클 경우 (패딩 블록이 생긴다)
- 내부 단편화는 “할당된 블록 크기 - 데이터 크기”로써 간단하게 정량화할 수 있다.
- 내부 단편화의 크기는 이전 요청 데이터의 크기와 할당기의 구현에만 의존된다. 즉 예측과 계산이 쉽다.
외부 단편화
- 할당 요청을 만족시킬 가용 공간이 전체적으로 모았을 땐 충분하지만, 이 요청을 처리할 “단일 가용블록”은 없는 경우이다.
- ( 즉 요청 크기를 만족할 단일 가용블록이 없을 경우 )
- 외부 단편화는 내부 단편화보다 훨씬 측정하기 어렵다. 이전 요청과 할당기의 구현에만 의존하는 것이 아닌, 미래의 요청에도 의존하기 때문. 이게 무슨 말이냐?
ex) 모든 가용 블록이 4워드 뿐일 때, 외부 단편화가 발생하는가?
-> 미래의 요청이 전부 4워드보다 작다면 외부 단편화는 발생하지 않는다.
-> 미래의 요청이 4워드보다 크다면 발생한다. 즉 미래 요청에 의존된다.
- 외부 단편화는 측정이 어렵고 예측이 불가하다.
- 따라서 할당기는 “많은 수의 작은 가용 블록”보다는 “적은 수의 큰 가용 블록”을 유지하려는 방향을 채택한다.
묵시적 가용 리스트
- 가용 블록이 헤더 내 필드에 의해 묵시적으로 연결된다.
- 할당기는 블록 경계를 구분하고 할당된 블록과 가용 블록을 구분하는 데이터 구조가 필요하며, 대부분 할당기는 이 정보를 블록 내에 저장한다.
- 가용 블록은 1워드 헤더, 데이터, 추가 패딩(옵션)으로 구성된다.
- 헤더는 블록 크기(헤더, 패딩 등을 포함한 크기)와 블록이 할당 상태인지 가용 상태인지를 포함한다.
## 아래 설명들은 묵시적 가용 리스트 중심의 내용이지만, 대체로 명시적 가용 리스트 내용과도 일맥상통하며 구체적인 구현 방식에서 약간의 차이가 있을 뿐이다. ##

1워드의 헤더 + 페이로드 + 패딩(옵션)
헤더의 마지막 비트의 값이 1이면 할당된 것, 0이면 가용 상태이다.
malloc은 payload의 시작 주소 를 리턴한다.
헤더엔 32비트의 값이 저장되어 있는데, 이것은 해당 블록의 크기와 allocated 여부이다.

묵시적 가용 리스트를 이용한 힙 (할당된 블록은 색이 칠해져 있다)
- 더블 워드 정렬 제한조건을 부여하면 블록 크기는 8의 배수이고 하위 3비트는 항상 0이다. (이진수 1000이 8 이니까)
-> 따라서 블록 크기의 상위 29비트만 저장하고 나머지 3비트는 다른 정보를 저장하기 위해 남겨둔다!!
-> 정확히는 32비트를 저장하되 상위 29비트는 주소, 나머지 3비트엔 allocated 정보를 포함한 다른 정보를 저장한다.
-> 사이즈를 확인할 땐 마지막 3비트를 0으로 만들어 확인하고, allocated 정보를 확인할 땐 마지막 1비트만 확인하는 방식.
- 헤더 다음엔 payload가 따라오고, payload 다음에는 패딩이 따라올 수 있다.
- 최소 정렬 기준에 맞추는 것이기 때문에 패딩의 크기는 가변적이다.
- 패딩은 외부 단편화를 극복하기 위한 전략일 수 있으며, 정렬 요구사항 때문에 필요할 수 있다. ( 근데 패딩 하면 내부단편화 잖아 -> 하지만 내부 단편화는 정량적 계산이 되니까 이게 나은 것 같다 )
묵시적 가용 리스트의 장/단점
- 장점 : 단순하다
- 단점 : 블록을 할당하기 위하 가용 리스트를 탐색하는 연산의 비용이, 힙에 있는 전체 블록의 수에 비례한다. ( 즉 일일이 봐야 할 수 있다, 선형적이다 )
할당기의 배치 정책(할당할 가용 블록을 찾는 기준)
- first fit, next fit, best fit 3가지가 주로 사용된다.
First fit
- 가용 리스트를 처음부터 검색해서, 크기가 맞는 첫 번째 가용 블록 선택
- 큰 블록들이 리스트의 뒤에 있는 경향이 있어, 큰 블록을 찾을 때 검색 시간이 늘어난다.
Next fit
- First fit과 비슷하나, 이전 검색이 종료된 지점부터 검색 시작
- 이전 검색에서 가용 블록을 발견했다면, 다음 검색에서는 리스트의 나머지 부분에서 원하는 블록을 찾을 가능성이 높다는 아이디어에서 착안됨
- First fit에 비해 매우 빠른 속도를 가지며, 리스트 앞 부분이 많은 작은 블록으로 구성되면 더욱 그렇다.
- 하지만 최악의 메모리 이용도는 first fit보다 낮다.
Best fit
- 모든 가용 블록을 검사하여 크기가 맞는 가장 작은 블록을 선택( 딱 맞는 거 선택 )
- 일반적으로 first, next보다 메모리 이용도가 높다.
- 묵시적 가용 리스트를 사용할 경우 힙을 완전히 다 검색해야 한다는 단점이 있다.
- 힙을 모두 검색하지 않는 명시적 가용 리스트인 segregated free list도 존재한다.
가용 블록의 분할
- 할당기가 가용 블록을 찾은 후에 어느 정도를 할당할 지 정책을 세워야 한다.
- 가용 블록 전체를 사용한다면 간단하고 빠르나, 내부 단편화가 생긴다. 크기가 맞는다면 괜찮지만...
- 크기가 맞지 않을 경우 대개 블록을 두 부분으로 나눈다.
- 첫 번째 부분은 할당 블록, 나머지는 새로운 가용 블록으로 나누게 된다.
추가적인 힙 메모리 획득하기
- 요청에 맞는 블록을 찾을 수 없다면, 인접 가용 블록들을 연결하여 큰 가용 블록을 만든다.
- 그래도 안 된다면 sbrk 함수를 호출하여 추가 힙 메모리를 요청하게 된다.
가용 블록 연결하기
- 할당된 블록을 반환할 때, 그 블록의 인접한 다른 가용 블록이 있을 수 있는데, 이 상황에서 “오류 단편화(false fragmentation)”를 일으킬 수 있다.
연결(coalescing)
- 오류 단편화를 해결하기 위해 인접 가용 블록들을 통합하는 것
- 언제 연결을 할 지에 대한 구체적인 정책을 정해야 한다.
즉시 연결
- 블록이 반환될 때마다 즉시 인접 블록을 통합하는 것
- 간단하며, 상수 시간에 수행된다
- 하지만, 연결된 후에 다시 분할되는 쓰레싱을 유발할 수 있다. 즉 불필요한 연결과 분할 연산들이 생길 수 있다.
지연 연결
- 연결하지 않고 있다가 더 큰 가용 블록이 필요할 때, 전체 힙을 검색하면서 모든 가용 블록을 연결하는 것
경계 태그 방식으로 연결하는 방법
헤더(Header)
- 현재 블록의 헤더(Header)는 다음 블록 헤더를 가리키고 있음, 따라서 다음 블록이 할당될 수 있는지 체크할 수 있다.
- 하지만 헤더만으론 이전 블록을 쉽게 찾아가기 어렵다.
풋터(Footer)
- 헤더를 복사한 것
- 풋터는 블록의 끝(헤더 반대편)에 위치하며, 다르게 말하면 다음 블록 헤더의 1워드(1블록) 이전에 위치한다.
- 할당기 입장에서 현재 위치에서 단 1워드만 뒤로 가면 풋터가 있기 때문에, 풋터를 통해 이전 블록의 상태와 시작 위치를 파악할 수 있다.
경계 태그의 방식의 단점
- 각 블록이 헤더/풋터를 유지해야 하기 때문에, 특히 많은 크기의 작은 블록이 있을 경우 상당한 메모리 오버헤드가 발생할 수 있음
mem_sbrk 함수

추가적인 힙 메모리를 요청하는 함수이다.
기존 brk 위치부터 입력받은 incr 값 만큼 힙을 추가 할당한다.
25~28행 : 힙 메모리를 줄이는 요청(incr이 음수)이 오거나 메모리 최대 주소를 초과한다면 오류와 함께 -1을 리턴한다.
30~31행 : brk를 incr만큼 늘리고, 늘리기 전의 기존 brk포인터를 리턴한다. 그래야 거기부터 데이터 쓸 테니까.

경계 태그를 이용한 힙의 형태는 이렇다.
패딩 블록(첫 번째 블록)
- 더블 워드 단위로 정렬되기 위한, 사용되지 않는 패딩 워드 (힙에 포함이긴 하다)
프롤로그 블록
- 패딩 블록을 제외한 힙의 가장 앞쪽에 존재하며, 힙의 시작을 의미한다
- 헤더와 풋터로만 구성된 8바이트 할당 블록(페이로드 없음)
- 초기화 과정에서 생성되며 절대 반환하지 않는다.
에필로그 블록
- 헤더만으로 구성된 0바이트 크기의 블록
- 힙 영역의 가장 뒤쪽에 존재하며, 끝을 의미한다
에필로그 블록 : 0/1인 이유
- 묵시적 가용 리스트에서 일반적으로 0/1은 존재할 수 없는 블록이다. 풋터 없이 헤더만 존재하고, 0바이트 크기는 존재할 필요도 없고 존재해서도 안 되기 때문이다. 따라서 고유성을 가지며, 힙의 끝을 구분할 수 있게 된다.
프롤로그 블록 : 8/1인 이유
- 에필로그 블록과 동일한 형태로 존재해야 하는 것 아닌가 하는 의문이 들 수 있다. 하지만 프롤로그 블록 또한 0/1로 존재하게 되면 에필로그 블록과 구분되지 않는다. 따라서 헤더와 풋터로만 구성된 블록으로 만든 것이다. 사실 헤더와 풋터로만 구성된 블록도 일반적으로 존재할 수 없다. 사용자가 malloc(0)이라는 명령을 하진 않을 테고 할 필요도 없으니까. 따라서 프롤로그 블록도 고유성을 가지며, 힙의 시작을 구분할 수 있게 된다.
static char *heap_listp
할당기는 한 개의 static 전역변수를 사용하는데, 이것은 항상 프롤로그 블록을 가리킨다.( 약간의 최적화를 통해 프롤로그의 다음 블록을 가리키게 할 수도 있다 )
다음 글에서 C언어를 이용해 동적 메모리 할당을 묵시적 가용 리스트 방식으로 구현해 보겠다.
'크래프톤 정글 > TIL' 카테고리의 다른 글
| [malloc-lab] 동적 메모리 할당 / 명시적 가용 리스트 방식 구현 (C언어) (2) | 2024.05.01 |
|---|---|
| [malloc-lab] 동적 메모리 할당 / 묵시적 가용 리스트 방식 구현 (C언어) (2) | 2024.05.01 |
| [크래프톤 정글 5기] week06 malloc-lab 주차 여섯번째 날, 페이징/세그먼테이션, DMA (0) | 2024.04.30 |
| Red Black Tree의 개념과 삽입/삭제, C언어 구현 (0) | 2024.04.23 |
| [크래프톤 정글 5기] week04 C언어 주차 여섯번째 날, 이진 검색 트리, B-Tree (0) | 2024.04.16 |