스프린트 3이 종료되었다. 스프린트 2 회고에서 차량 등록, 조회를 어떻게 구현할지 걱정했지만 훌륭히 구현해 냈다.
이번에 구현한 기능은 아래와 같다.
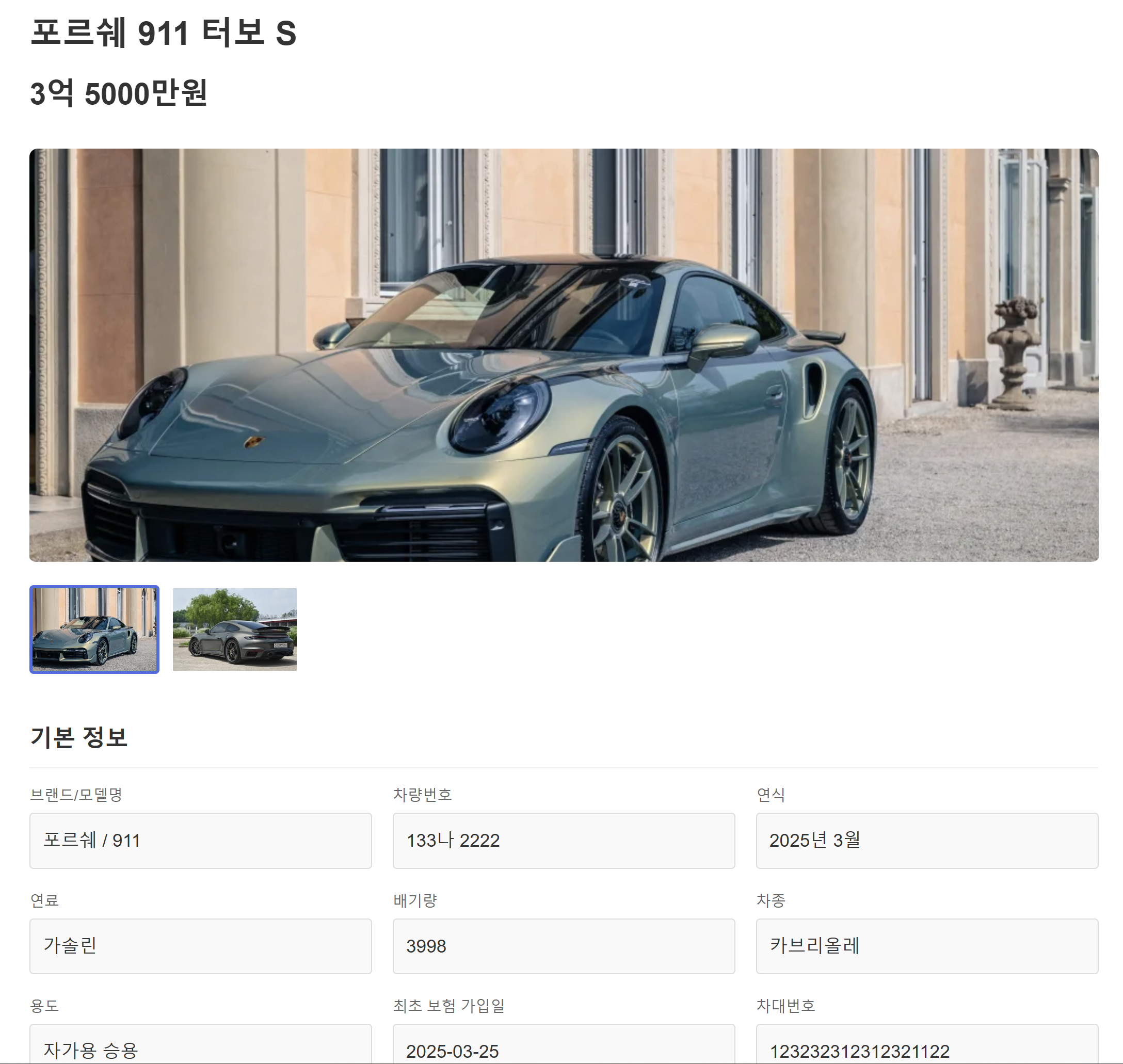
- 차량 등록
- 판매 차량 상세 조회
차량 정보를 다루는 엔티티가 무려 10개였기 때문에, 백엔드 코드 작성이 매우 매우 어려웠다. 애플리케이션 레벨에서 관계는 어떻게 정의하며, repository와 service는 어떤 구조로 작성하고 관리하는지, 쿼리는 어떻게 최적화 하는지 등등… 고민해보지 못했던 문제들을 많이 만났다. 스프린트 2의 유저 관련 로직을 짤 때보다 10배는 더 어려웠던 것 같다.
이번 스프린트 3을 진행하며 가장 크게 배운 것은 객체지향적 설계와 SOLID원칙, 그리고 쿼리 최적화이다.
백엔드에서 어려웠던 점 - 객체지향적 설계와 N+1, 카테시안 곱 문제 해결과 최적의 쿼리 작성
객체지향적 설계
많은 엔티티를 다루니 repository도 많고 service도 많았다. 차량 등록에 필요한 create 메서드를 서비스 레벨에 따로 작성할까, 아니면 그냥 바로 repository를 호출해서 작성할까 고민했고, 의존하는 서비스가 많았기 때문에 Facade 패턴도 고려했다. 또한 각종 SOLID 원칙을 고려해서 코드에 도입했고, 내가 작성한 코드가 어떤 원칙에 부합하는가/하지 않는가를 계속해서 생각했다.
결과적으로 service는 각 엔티티별로 따로 두되 Facade 서비스를 따로 만들어서 거기서 각 service를 호출해 비즈니스 로직을 작성했고, 인터페이스는 구현체가 불필요한 메서드를 구현하지 않도록 세분화 했으며, 반복되는 엔티티 ↔ DTO 변환용 정적 팩토리 메서드는 전부 삭제하고 MapStruct를 도입하여 최적화했다. 또한 더미 데이터 생성 메서드나 랜덤 값을 뱉는 메서드는 util 패키지 하위에 따로 분리하여 구현함으로써 SRP 원칙을 지켰으며, 더미 데이터 생성 로직이 prod환경에서 동작하지 않도록 dev 개발환경을 분리하였다.
객체지향적 설계를 계속해서 고려하며 코드를 짜니 조금은 익숙해진 기분이다. 점점 코드를 어떤 식으로 짜야 좋은 설계인지를 자연스럽게 이해하고 있는 것 같다.
쿼리 최적화 ( N+1, 카테시안 곱 )
차량 상세조회 기능을 구현하며 쿼리 최적화 과정을 맛보았다.
정말정말 끔찍했다. 나는 쿼리 짜는 실력이 정말 형편없구나 라는 걸 한번 더 느꼈다. 그러나 정말 많이 배웠다. 10개나 되는 엔티티를 어떻게 조회해야 문제가 생기지 않고 성능도 챙길 수 있을까? 를 정말 많이 고려했다.
가장 많이 접한 키워드가 Lazy Loading, fetchJoin(), BatchSize, 영속성 컨텍스트 이다. 4개 다 정확히는 모르는 개념들이었다. Lazy Loading을 왜 적용하는지도 몰랐고 쿼리 작성 시 N+1 이나 카테시안 곱 문제가 발생할 수 있다는 것도 스프린트3 전에는 잘 인지하지 못했었다.
Lazy Loading은 연관 엔티티 데이터를 초기 쿼리 한 번에 로드하지 않고 실제로 접근하는 시점에 추가 쿼리를 실행하여 데이터를 가져오는 개념이다. 그러나 여러 엔티티 데이터가 필요해 join을 사용해 여러 엔티티를 조회할 경우, JPA의 영속성 컨텍스트 관리 특성 때문에 쿼리로는 한 번에 데이터를 가져왔음에도, 영속성 컨텍스트에는 주 엔티티 데이터만 등록되어 연관 엔티티를 조회할 때 마다 추가 쿼리가 발생하며 N+1 문제를 야기한다. 이것을 해결하기 위해 fetchJoin()을 붙여야 하는데, 이것은 영속성 컨텍스트에 join으로 가져온 데이터를 초기에 전부 로드하는 옵션이며, 단 한 번의 쿼리로 데이터를 전부 가져오도록 강제한다. 따라서 N+1 문제가 방지된다.
그러나 1:1 또는 N:1 관계(ToOne)가 아닌 1:N 관계(ToMany)에서 fetchJoin() 옵션을 사용할 경우 카테시안 곱 문제가 발생할 수 있다. 따라서 fetchJoin은 ToOne 관계에서만 사용해야 한다. 그러면 어떻게 toMany 관계에서 N+1 문제를 방지할 수 있는가? 바로 BatchSize 설정이다. 연관 엔티티 N개에 접근할 때 N개 쿼리가 발생하던 것을, BatchSize 설정 값 만큼의 엔티티를 IN 구문을 사용해 한 번에 가져오므로 N+1문제를 효과적으로 방지한다. 추가로, join 쿼리로 가져오는 것이 아니기 때문에 카테시안 곱 문제도 방지된다.
이렇게 새롭게 배운 개념들을 적용하여 쿼리를 작성했다. ToOne 관계인 엔티티들은 fetchJoin으로 조회했고, ToMany 관계 엔티티들은 전부 개별 쿼리로 조회하고 BatchSize를 전역 적용해서 N+1, 카테시안 곱 문제를 전부 방지했다. 또한 조회 결과는 record로 구현된 래퍼 클래스에 담아서 리턴하고, 데이터 후처리 로직은 리소스가 충분한 애플리케이션 레벨에서 하는 게 좋기 때문에 서비스 계층에서 데이터를 받아 Mapper와 함께 후처리했다.
나름대로 내 수준에서 할 수 있는 최선의 방법을 사용했다고 생각한다. 정말정말 어려웠지만, 앞으로는 어떤 복잡한 쿼리를 짜든 간결하고 효율적으로 짤 수 있을 것 같다는 자신감이 조금 생겼다.
아래는 Lazy Loading, fetchJoin(), BatchSize에 대해 내가 정리한 글과 차량 상세조회 기능 구현 과정을 담은 포스팅이다.
https://yskisking.tistory.com/316
JPA 쿼리 최적화 - Lazy loading, fetchJoin(), BatchSize
개인 프로젝트 썬카에서 차량 상세 조회 기능을 만들다가 쿼리 최적화 문제에 부딪혔다.무려 10개의 엔티티를 전부 조회해야 했고 성능 부분을 신경쓰지 않을 수 없었기에, 자연스럽게 Lazy loading
yskisking.tistory.com
https://yskisking.tistory.com/317
[썬카/백엔드] 판매 차량 상세조회 기능 구현 - Lazy Loading, fetchJoin(), BatchSize
차량 상세조회 기능을 구현하며 차량 관련 엔티티 10개를 조회해야 했는데, 이 과정에서 Lazy Loading, fetchJoin, BatchSize를 공부하고 적용해 보았다. 백엔드에서 쿼리 짜는 게 제일 어려운 것 같다. 아
yskisking.tistory.com
================
프론트엔드는 점점 관심도가 떨어지고 있다. 클로드가 프론트 코드를 너무나 잘 짜주는 것도 있고, 백엔드보다 고려할 게 더 적은 것 같다. 뭐랄까.. 그냥 얕고 넓은 느낌이다. 애초에 프론트엔드에 크게 투자하지 않으려고 생각했던 것도 있지만, 내 취향에도 맞지 않는다는 걸 느낀다. 이제 프론트엔드 코드 품질은 사실상 신경 껐고, 백엔드와 어떻게 연동되는지 정도에만 초점을 두고 구현 중이다.
백만 해도 충분히 어렵고 고려할 게 많은데 굳이 프론트엔드에 큰 투자 할 필요 없는 것 같다. 프론트엔드에 신경을 많이 쓰는 것이 백엔드 실력에 드라마틱하게 도움이 될 것 같지 않다는 실감이 들고 있다. 오히려 백에서 했던 것들이 프론트 구현할 때 도움이 되는 느낌까지 든다.
그러나 프론트에 신경을 덜 쓸수 있는, 템플릿 엔진을 사용한 전통적인 MVC 패턴으로 프로젝트를 시작하지 않은 것을 후회하진 않는다. 실무에서는 RestAPI 방식을 가장 많이 사용하고 있고, 해당 패턴에 맞춰 프로젝트를 진행하는 것이 더욱 가치있다고 생각한다. 프론트 구현이 조금 귀찮긴 한데, 그렇게 크게 어렵지도 않을 뿐더러 어차피 클로드가 잘 짜주니까 나는 전체적인 흐름만 이해한다는 느낌으로 가면 챙길 건 다 챙기는 가장 효율적인 방법이라고 생각한다.
=============
썬카 노션
https://lava-move-d1e.notion.site/SunCar-1a754e6b788180f598cdea3bfaff3139?pvs=4
깃허브
'Development > 썬카(SunCar) - 개인 프로젝트' 카테고리의 다른 글
| [썬카/백엔드] 커스텀 쿼리를 이용한 판매 차량 삭제 기능 구현 - Soft Delete 방식의 간접 CASCADE (0) | 2025.04.18 |
|---|---|
| [썬카/백엔드] 서비스 계층 및 커스텀 리파지터리 테스트 코드 작성, 팩토리/빌더 클래스 설계와 영속성 컨텍스트, Hibernate 통계 관리(Statistics) (0) | 2025.04.18 |
| [썬카/백엔드] 판매 차량 상세조회 기능 구현 - Lazy Loading, fetchJoin(), BatchSize (0) | 2025.04.08 |
| [썬카/백엔드] 차량 관련 Facade 서비스 인터페이스 세분화 (LSP, ISP 원칙) (0) | 2025.04.04 |
| [썬카/백엔드] 차량 판매등록 기능 구현 - 더미 데이터 생성과 객체지향적 설계 (0) | 2025.04.03 |